Using GCP, FastAPI, Docker, and Huggingface to Deploy SOTA Language Models
I have found using more than 2 models is too large for most deployed containers. If you know a way around this let me know.
Initial Set Up
This stack will use FastAPI to serve an endpoint to our model. FastAPI requires uvicorn for serving, and pydantic to handle typing of the request messages. The Huggingface Transformers library specializes in bundling state of the art NLP models in a Python library that can be fine-tuned for many NLP tasks like Google's BERT model for named entity recognition or the OpenAI GPT2 model for text generation.
Using your preferred package manager, install:
-
uvicorn
-
pydantic
As the packages install:
- Create a folder named app
- Add files
nlp.pyandmain.pyto it - In the top-level directory, add Dockerfile and docker-compose.yml
After installing packages, create a requirements folder and add requirements.txt:
Since I used pipenv to manage the python environment, I had to run:
pipenv run pip freeze > requirements/requirements.txt
You will need this folder later for building the Docker container. While we are on the topic, be sure you have installed docker and check to be sure the following are installed.
The project structure should look like this:
app/
main.py
nlp.py
requirements/
requirements.txt
docker-compose.yml
Dockerfile
PipfileNLP
Hugging Face makes it really easy to implement and serve sota transformer models. Using their transformers library, we will implement an API capable of text generation and sentiment analysis. This code has been ripped straight from the site, so I will not be deep diving the transformer architecture in this article for time's sake. This also means our models are not fine tuned for a specific task. Please see my next article on fine tuning and deploying conversational agents in the future. With that disclaimer out of the way, let's look at a snippet of the code responsible for our NLP task. Code Snippet
from transformers import (
pipeline,
GPT2LMHeadModel,
GPT2Tokenizer
)
class NLP:
def __init__(self):
self.gen_model = GPT2LMHeadModel.from_pretrained('gpt2')
self.gen_tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
def generate(self, prompt="The epistemelogical limit"):
inputs = self.gen_tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
)
prompt_length = len(self.gen_tokenizer.decode(
inputs[0],
skip_special_tokens=True,
clean_up_tokenization_spaces=True
))
outputs = self.gen_model.generate(
inputs,
max_length=200,
do_sample=True,
top_p=0.95,
top_k=60
)
generated = prompt + self.gen_tokenizer.decode(outputs[0])[prompt_length:]
return generated
def sentiments(self, text: str):
nlp = pipeline("sentiment-analysis")
result = nlp(text)[0]
return f"label: {result['label']}, with score: {round(result['score'], 4)}"
This is a very simple class that abstracts the code for text gen and sentiment analysis. the prompt is tokenized, the length of the encoded sequence is captured, and output is generated. We then receive the decoded output and return it as the generated text. The text returned for generate() will look something like:
The epistemological limit is very well understood if we accept the notion that all things are equally good. This is not merely an axiom, but an axiomatical reality of propositions, including the notion that the things on the left of the triangle do not constitute a thing, such that that thing can neither be said to exist nor to exist as a thing apart from something on the right of that triangle, nor to be a thing apart from something else on the left of that triangle. Thus if we suppose that each thing must lie on the line of a triangle, as there is a line across this triangle, then each thing cannot lie on that line; but only as there are points beyond this point, so that nothing has a right angle to the triangle. Hence the proposition “the things on the right of a triangle do not constitute a thing” is a fact, which presupposes a fact, which can be the proposition that no thing exists. On the other hand, suppose that if
Godel would be proud!
Sentiment analysis is easier due to the pipeline huggingface provides. Simply pass in text to the pipeline and return it.
nlp = NLP()
print(nlp.sentiments("A bee sting is not cool"))
# Output: 'label: NEGATIVE, with score: 0.9998'API using FastAPI
FastAPI is one of the fastest API frameworks to build and serve API requests in python. It can be scaled and deployed on a docker image they provide or you can create your own from a python image. If you have ever written a Flask API then this should not be difficult at all. I advise going through the FastAPI documentation for more info on how to extend functionality of your API.
Our server will look like this:
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from app.nlp import NLP
class Message(BaseModel):
input: str
output: str = None
app = FastAPI()
nlp = NLP()
origins = [
"http://localhost",
"http://localhost:3000",
"http://127.0.0.1:3000"
]
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["POST"],
allow_headers=["*"],
)
@app.post("/generative/")
async def generate(message: Message):
message.output = nlp.generate(prompt=message.input)
return {"output": message.output}
@app.post("/sentiment/")
async def sentiment_analysis(message: Message):
message.output = str(nlp.sentiments(message.input))
return {"output": message.output}
The API has four sections. The first part is setting up a pydantic object to handle typing for request messages. This means we get input validation and clear error messages for the wrong input. You should only be handling strings so this is perfect. We then create an instance of the endpoint and the NLP class. Next, set up the request origin URLs that you want your app to communicate with. If you do not have dedicated origin addresses, the code will still run, but anyone can access your API so be careful. After that, we set up the middleware to control the origins, request methods, headers, and cookies. I have taken most of the code from FastAPI but it is extensible to your particular security needs. The last part contains two async post request methods that handle the calls to the API and return the generated text or sentiment analysis.
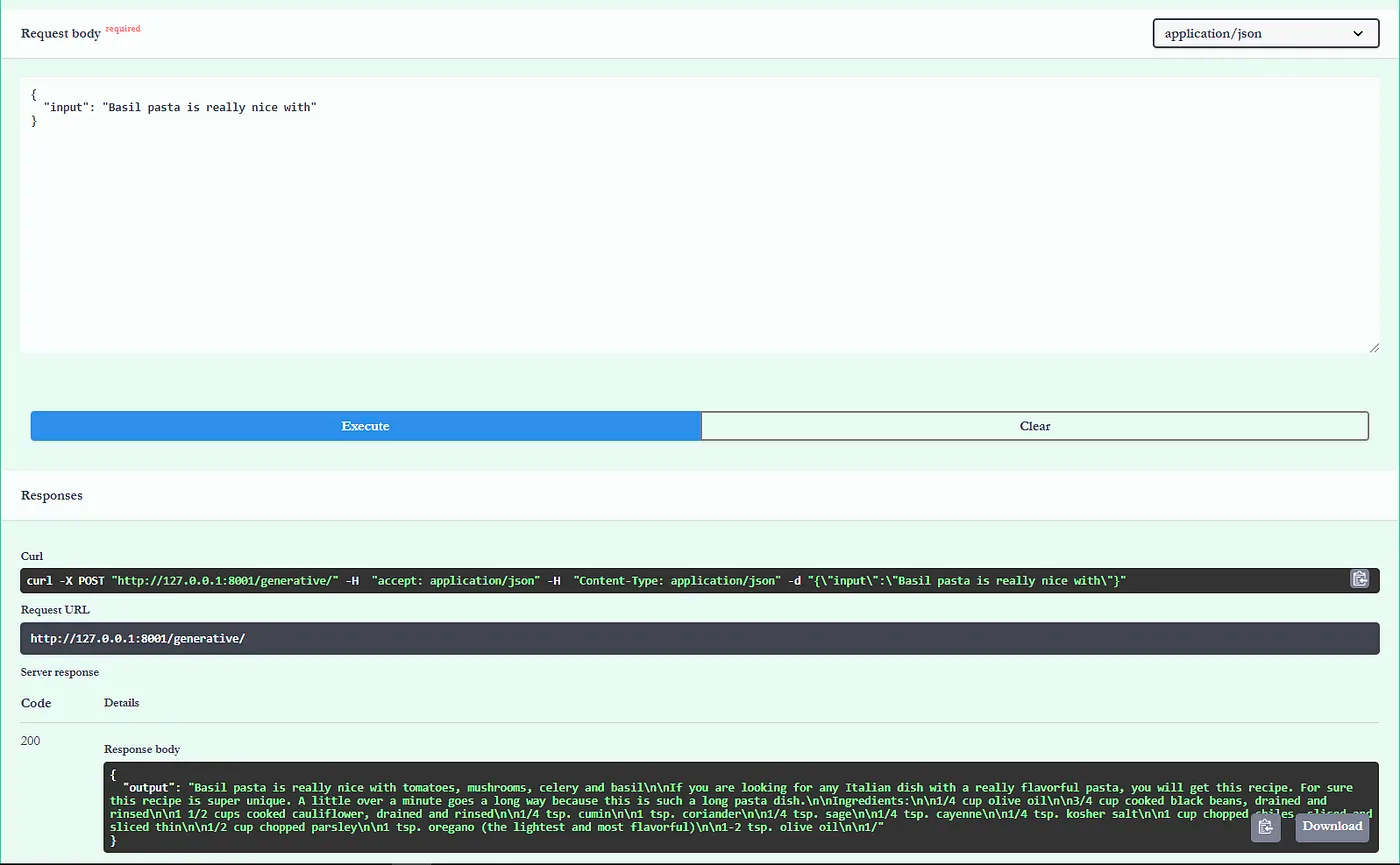
To test the API:
uvicorn app.main:app --reloadVisit http://127.0.0.1:8001/docs to try out the API.
Containerization
Remember that Dockerfile file we created? It’s finally time to edit that. The container I made uses a python:3.7 image. You are free to tweak this to fit your python image preference.
FROM python:3.7
COPY ./requirements/requirements.txt ./requirements/requirements.txt
RUN pip3 install -r requirements/requirements.txt
COPY ./app /app
RUN useradd -m myuser
USER myuser
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]The container will copy the requirements to the container, install them, copy over the files from the app directory, create a user (not necessary), and run the API on the container. Yes it is that simple. With regular docker commands we have to stop the container, rebuild the image, and start the container each time. To avoid this, add the following to your docker-compose.yml. Note that your container name can be whatever you want.
version: "3"
services:
chatsume:
build: .
container_name: "chsme"
ports:
- "8000:8080"
volumes:
- ./app/:/appBuild and run:
This allows us to rebuild the image and container and spin it up in one line: docker-compose build docker-compose up -d
Google Cloud Platform Deployment
After setting up the gcloud SDK you will be able to push docker images to your GCP project. The image will be pushed to the Google Container Registry in your project dashboard. To do so, we’ll tag our image with the gcloud region you want it stored in. For this example, the Docker image will be named nlp_api and the GCP project is fast_hug. The image will then be tagged as the latest one, which is great for keeping up with multiple pushes to your Google Container Registry Instance.
docker tag nlp_api gcr.io/fast_hug/nlp_api:latestPush to Google Container Registry:
docker push gcr.io/fast_hug/nlp_api:latestCloud Run Deployment
- Navigate to Google Container Registry
- Find your latest image
- Click Deploy
- Select Deploy to Cloud Run
- Allow unauthenticated requests (if you want a publicly consumable API)
- Click next then advanced settings.
- Set container port to 8080 (or whatever port value you mapped in the docker-compose yml)
- Set memory to 4GB
- Click Create
Success!!!! You have now set up and deployed a state of the art NLP model.
Conclusion
This post demonstrates how to use state-of-the-art NLP models from Huggingface to power a fast, scalable API. Containerization enables distributed deployment across various services and easy local development. In the future I will try deploying larger models for higher accuracy, at least until GPT3 is publicly consumable. For now, you have all the tools needed to rapidly scale a service backed by the latest in available NLP tooling.